Faraday Achieves State-of-the-Art Performance on Ether0 Chemistry Benchmark
Dec 4, 2025

We are excited to announce that Faraday, our AI scientist for drug design, has achieved state-of-the-art 51.3% accuracy on the multiple-choice question (MCQ) subset of the Ether0 benchmark, representing the highest score among all general LLMs and domain-specific AI agents evaluated to date. The beta version of Faraday is now available on our platform. New users can access it by requesting an access link.
In this post, we cover:
Introducing Faraday
Why we selected the Ether0 MCQ subset as our benchmark
Faraday’s results on Ether0
Faraday’s Capabilities Beyond Benchmarks
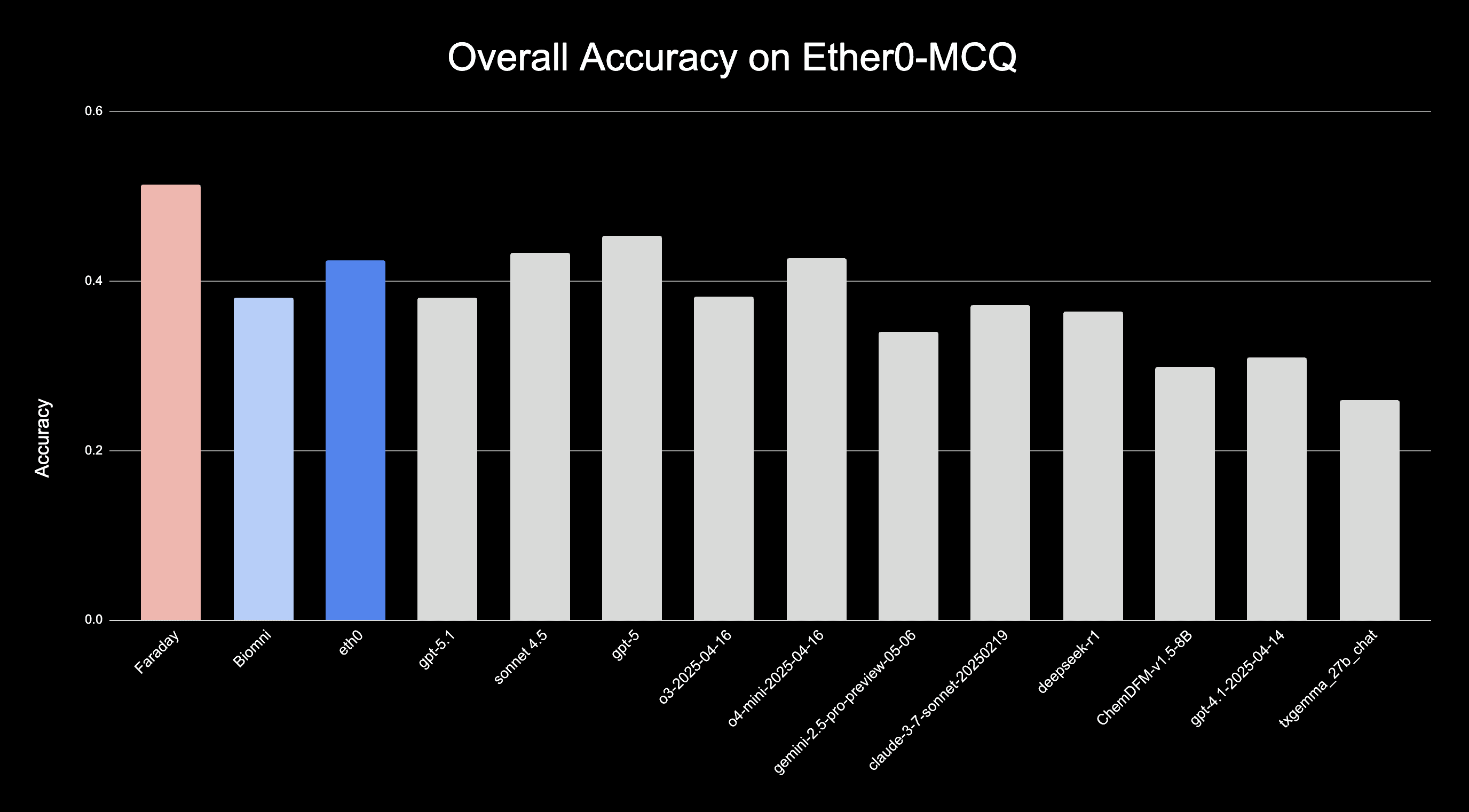
Figure 1. Faraday achieves state-of-the-art performance on Ether0 MCQs. Our system attains 51.3% accuracy, surpassing previous models including Ether0, Biomin, O3, O4-mini, Gemini-2.5, Claude 3.7, DeepSeek, ChemDFM, GPT-4.1, TXGemma, Sonnet 4.5, GPT-5 and GPT-5.1
Introducing Faraday
Faraday is an AI scientist agent engineered to autonomously solve multi-step drug design and scientific research problems. Given a research objective, Faraday systematically decomposes the task, executes computational workflows, and returns detailed solutions with supporting data visualizations.
Faraday operates within a containerized environment equipped with a file system and carefully designed library of capabilities, combining:
Deep research: The agent carries out complex drug design tasks by synthesizing available data, running specialized tools and models, and performing multi-step analysis.
Multi-modal information retrieval: Faraday can retrieve data from multiple sources including from scientific literature, specialized chemical/biological databases, and patents.
A unified scientific context: The agent operates within a platform-level context where each generated or retrieved file, tool output and message is carefully managed in the context window.
Parallel science: Scientists can also launch multiple tasks at the same time and monitor their progress to enable scalable hypothesis testing.
Built on an infrastructure that enables fast code execution, specialized model inference, and data retrieval, Faraday is a highly capable and reliable AI scientist for drug developers and life science researchers.
Why Ether0
Benchmarking scientific agents is hard. A few leading benchmarks in the space are BixBench, Eval1, and Ether0. BixBench (FutureHouse) and Eval1 (Biomni) assess general biological reasoning and bioinformatics capabilities and while good benchmarks, we chose Ether0 due to its relevance to chemical reasoning. Benchmarks assessing the strengths of AI agents on chemistry-oriented topics like molecular design continue to be largely underexplored. However these benchmarks are invaluable to monitoring the progress of AI agents for drug design.
Ether0-benchmark is a comprehensive benchmark developed by FutureHouse initially to evaluate their Ether0 reasoning language model, a scientific reasoning model for chemistry. The benchmark comprises 325 questions covering a diverse range of tasks, with 25 questions per task. These tasks include completing SMILES fragments, designing molecules under specified molecular formula and functional group constraints, predicting reaction outcomes, proposing one-step synthesis pathways, modifying molecular solubility, and converting IUPAC names to SMILES. Importantly, the benchmark includes 150 multiple-choice questions (MCQ) addressing key chemical properties and considerations, including safety, ADME (absorption, distribution, metabolism, and excretion) characteristics, human receptor binding, toxicity, scent, and pKa values.
For this evaluation, we focus exclusively on the MCQ subset because these questions pose straightforward challenges that test molecule recognition and understanding. They provide a clean, objective measure of chemical reasoning, covering nuanced topics that require genuine chemical intuition rather than simple pattern completion. In addition, MCQs allow for standardized, reproducible scoring, enabling straightforward comparisons across models and facilitating rapid, large-scale evaluation. By using the publicly available benchmark, we focus on the model’s core reasoning performance under standardized zero-shot evaluation conditions.
Additionally, by having experienced medicinal chemists from the biotechnology and pharmaceutical industry review the multiple-choice questions (MCQs), we confirmed that these questions are generally challenging to answer directly, even for trained professionals.
Below are some examples of questions from the Ether0-benchmark dataset:
Identify the molecule below expected to have a rat microsomal stability in mL/min/kg around 1.97:
C1=C(C(=O)NC2=NN=CS2)C=NC=C1
N1=CC(C(=O)NCC2=CC=CS2)=CC=C1
C1=C(C=NC=C1)CNC(C1C=CC(=CC=1)N1C(C)=CC(=N1)C)=O
C1=C(C=NC=C1)C(=O)NCC1=CC=C(C)N1C
Question 1f9f5787-63ca-50d7-b393-476b68b65c78
If molecule CC1=C[C@@H]2[C@H](CC[C@]3([C@H]2CC[C@@]3(C(=O)C)O)C)[C@@]4(C1=CC(=O)CC4)C is Growth hormone secretagogue receptor Antagonist, which of these related structures will most probably not have that property?
CC(=O)[C@]1(CC[C@@H]2[C@@]1(CC[C@H]3[C@H]2CCC4=CC(=O)CC[C@]34C)C)O C[C@H]1C[C@@H]2[C@H](CC[C@]3([C@H]2CC[C@@]3(C(=O)C)O)C)[C@@]4(C1=CC(=O)CC4)C C[C@]12CCC(=O)C=C1CC[C@@H]3[C@@H]2C(=O)C[C@]4([C@H]3CC[C@@]4(C(=O)CO)O)C CC(=O)S[C@@H]1CC2=CC(=O)CC[C@@]2([C@@H]3[C@@H]1[C@@H]4CC[C@]5([C@]4(CC3)C)CCC(=O)O5)C
Question ID: 5ede4df7-1004-517b-af8b-386e18facb62
Faraday's Results on Ether0
Faraday achieves the highest accuracy on the Ether0 multiple-choice question (MCQ) subset, outperforming all evaluated general and domain-specific agents (Figure 1). Across the six question categories, each comprising 25 questions, Faraday attains state-of-the-art performance in four categories—safety, ADME, pKa, and LD50 (tying with Biomni on LD50)—and ranks among the second-best performers for scent (Figure 2).
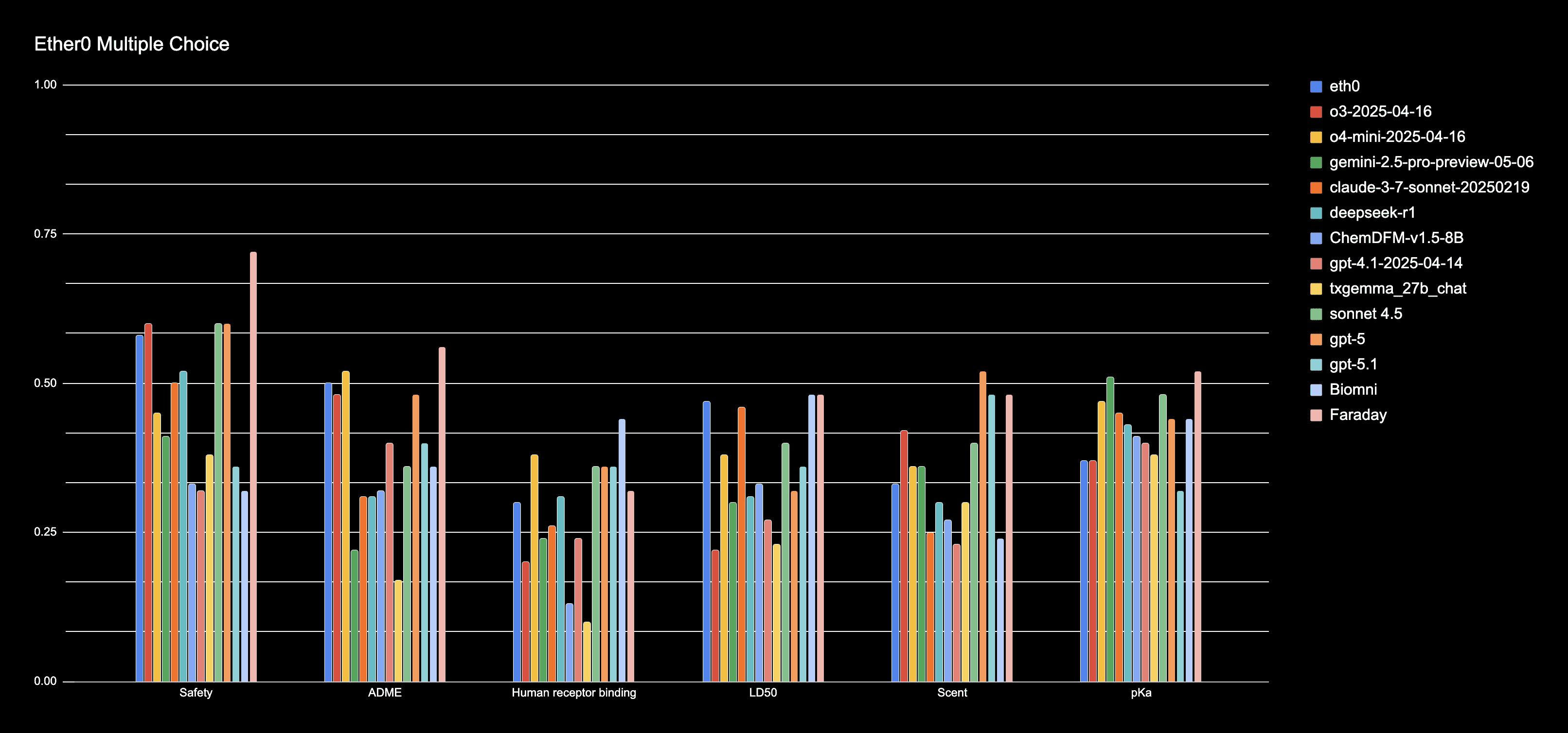
Figure 2. Faraday’s performance on each sub category compared to other models/agents
Importantly, we tested Faraday on the exact same platform our users access, ensuring that benchmark performance translates directly to real-world user experience. To see Faraday in action, you can also check out our demo video here.
Faraday’s Capabilities Beyond Benchmarks
Faraday is a highly capable and reliable AI scientist for drug design, extending far beyond the scope of benchmark questions. While it performs strongly on MCQs, its true strengths lie in generative and transformational chemistry capabilities, which currently lack standardized benchmark datasets but are extremely useful in real-world applications. These capabilities include:
Molecular Design: Proposing novel molecules or modifications that satisfy constraints such as molecular formulas, functional groups, or desired properties.
SAR Exploration and Property Reasoning: Evaluating chemical properties, safety, and ADME characteristics to prioritize candidates for downstream experiments.
Multi-Dimensional Data Analysis: Integrating and interpreting multi-dimensional datasets (eg. MOA+chemistry + clinical+ commercial) to extract actionable insights.
Open-Ended Discovery Questions: Answering complex, exploratory questions to guide research and hypothesis generation.
Competitive intelligence and clinical insights: while it specializes in drug design tasks, it also handles competitive intelligence and clinical data analysis related to drug molecules very well.
All outputs are scientifically presentation-ready and fully traceable, allowing chemists to validate results, understand the reasoning behind suggestions, and confidently integrate them into decision-making.
Get Access
Faraday is currently in beta testing, with early results indicating strong potential to accelerate drug discovery and support scientists across a wide range of tasks. If you’re interested in trying the beta version of Faraday, sign up for access here.
—-
Footnotes:
It is important to clarify that the evaluation presented here uses the Ether0-benchmark test set provided in the Ether0 repository, with results based on the released model weights. This ensures consistency with the evaluation framework and allows for reproducibility and transparent comparisons.
This differs from the Ether0 preprint, which reports results from pre-safety mitigation benchmarks and in-context learning (ICL) modifications. The ICL evaluation uses modified test sets for one-shot and zero-shot settings that have not been fully released. Specifically, ICL prompts are constructed by selecting one distractor (i.e., an incorrect option) from the original question and appending it as a labeled example; to maintain consistent baselines, the selected distractor is removed from the actual question. As a result, the overall accuracy reported in the preprint differs from the results obtained using the benchmark questions as distributed in the repository. By using the publicly available test set, we focus on the model’s core reasoning performance under standardized evaluation conditions.